Learning Neural Network usually seems difficult due to lots of math and terminologies used inside. However, to get started it is better to understand basic concepts first, without deep diving into underlying math and different variations of neural networks. In this article, we will walk through those fundamental concepts in order to get an idea of what is Neural Network, why we need it, and how it works.
Why use a Neural Network?
Usually, software engineers solve problems using an algorithmic approach.
However, sometimes it is difficult or even impossible to write an algorithm for certain types of problems, like image classification, speech recognition, etc. And here comes Neural Networks.
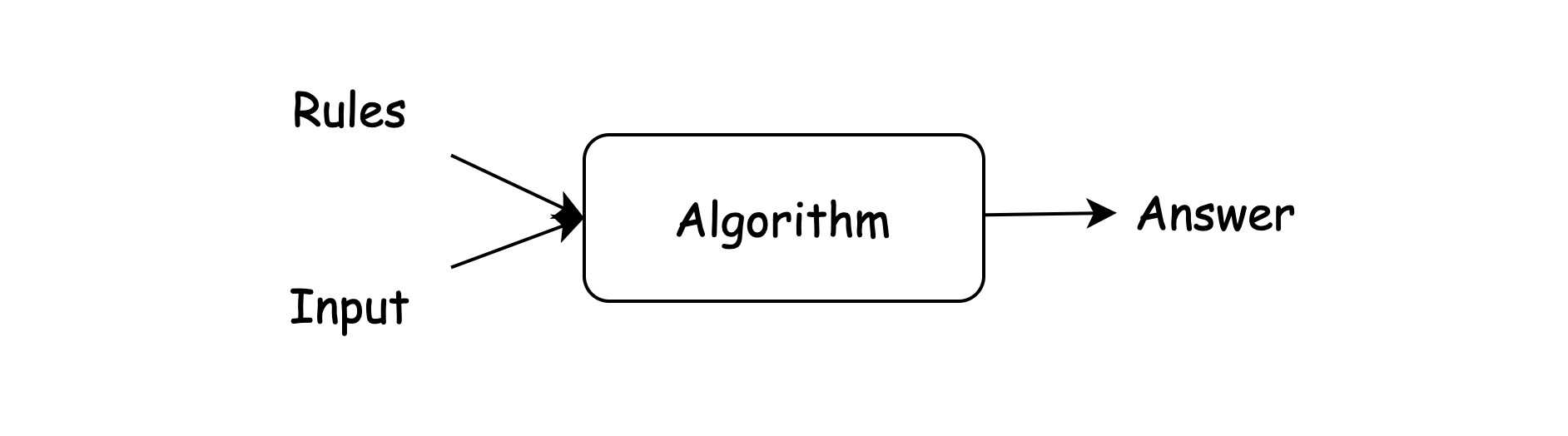
Algorithmic approach
You specify rules (algorithm) and then get the result (answer)
Neural Network approach
You provide existing results (examples) to get the rules
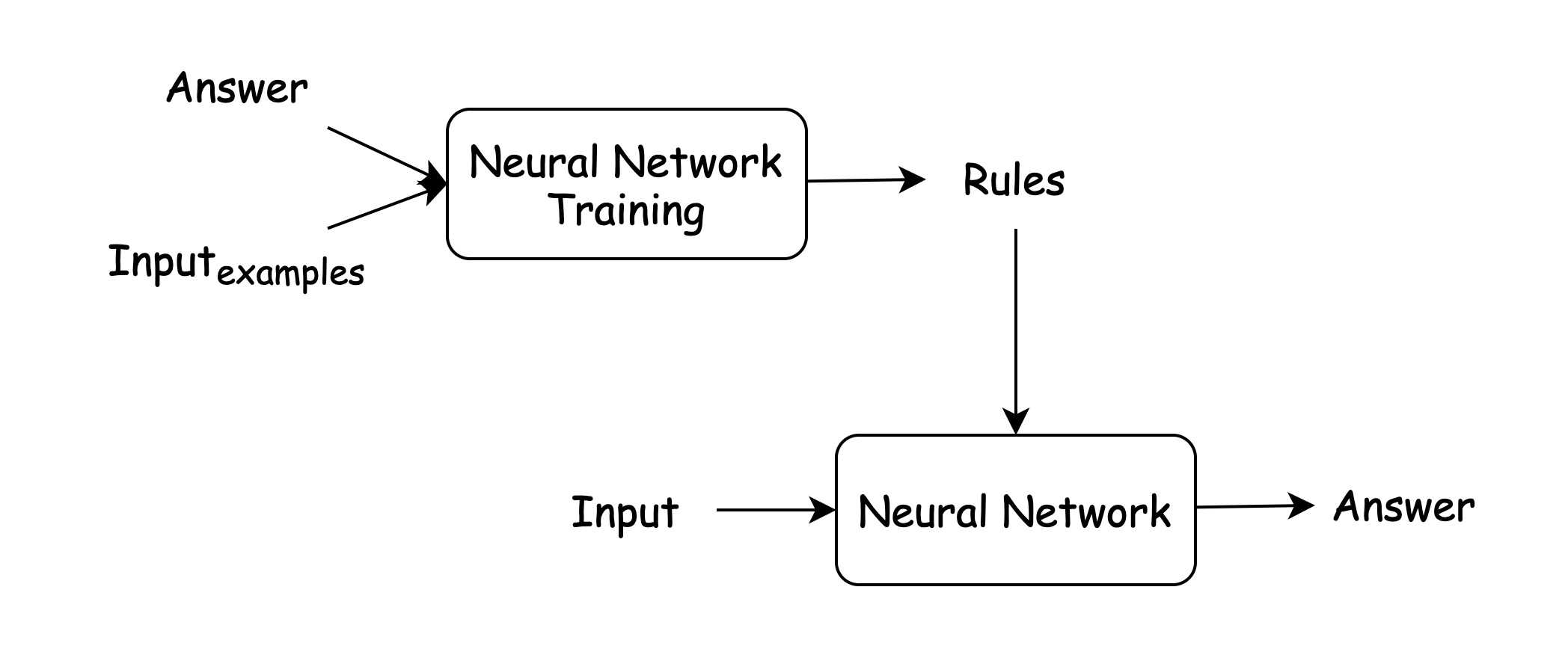
Under the hood, Neural Network still uses many different algorithms to do its work.
Getting Started with Neural Networks
In order to get an idea of what is Neural Network, let’s just get a very general idea of how our mind activity works.
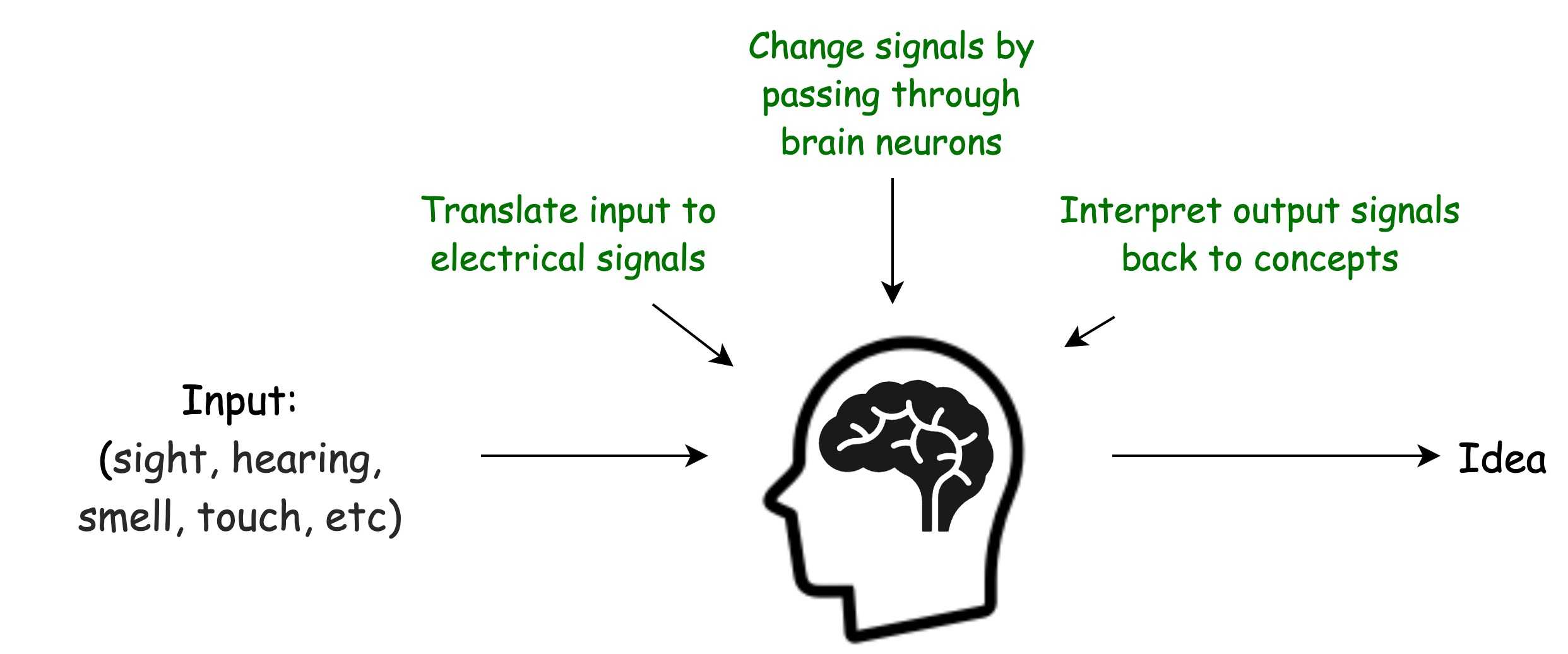
Many Deep Learning Experts don’t like “Brain” & “Neural Network” comparison, because human brain is much more complicated system which is even now not fully understood.
However, for the ease of understanding, we will anyway use this very simplified comparison.
Apparently, a Neural Network, similar to the brain, is made up of individual neurons.
Let’s dive deeper and get an idea of what is a single Neuron.
What is a Neuron?
Biological neuron
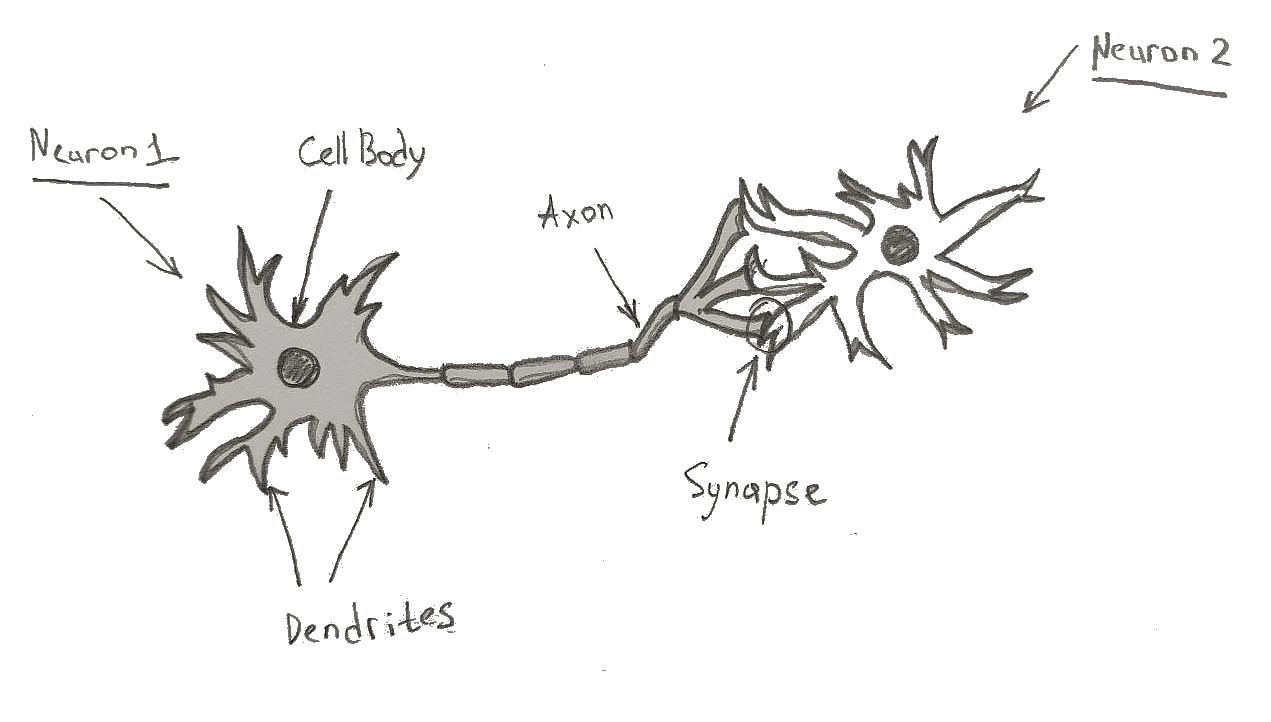 The key features of a biological neuron, that we are interested in, are:
The key features of a biological neuron, that we are interested in, are:
- Dendrites — receive an electrical signal
- Cell body — changes/modifies the signal
- Axon — passes a signal to other neurons
- Synapse — a connection point where one neuron’s axon connects to another neuron’s dendrite
“The average human brain has about 86 billion neurons and many more neuroglia (or glial cells)” — https://human-memory.net
So depending on connection strength in the synapse, a signal from one neuron gets increased or decreased while passing to another neuron.
Artificial Neuron
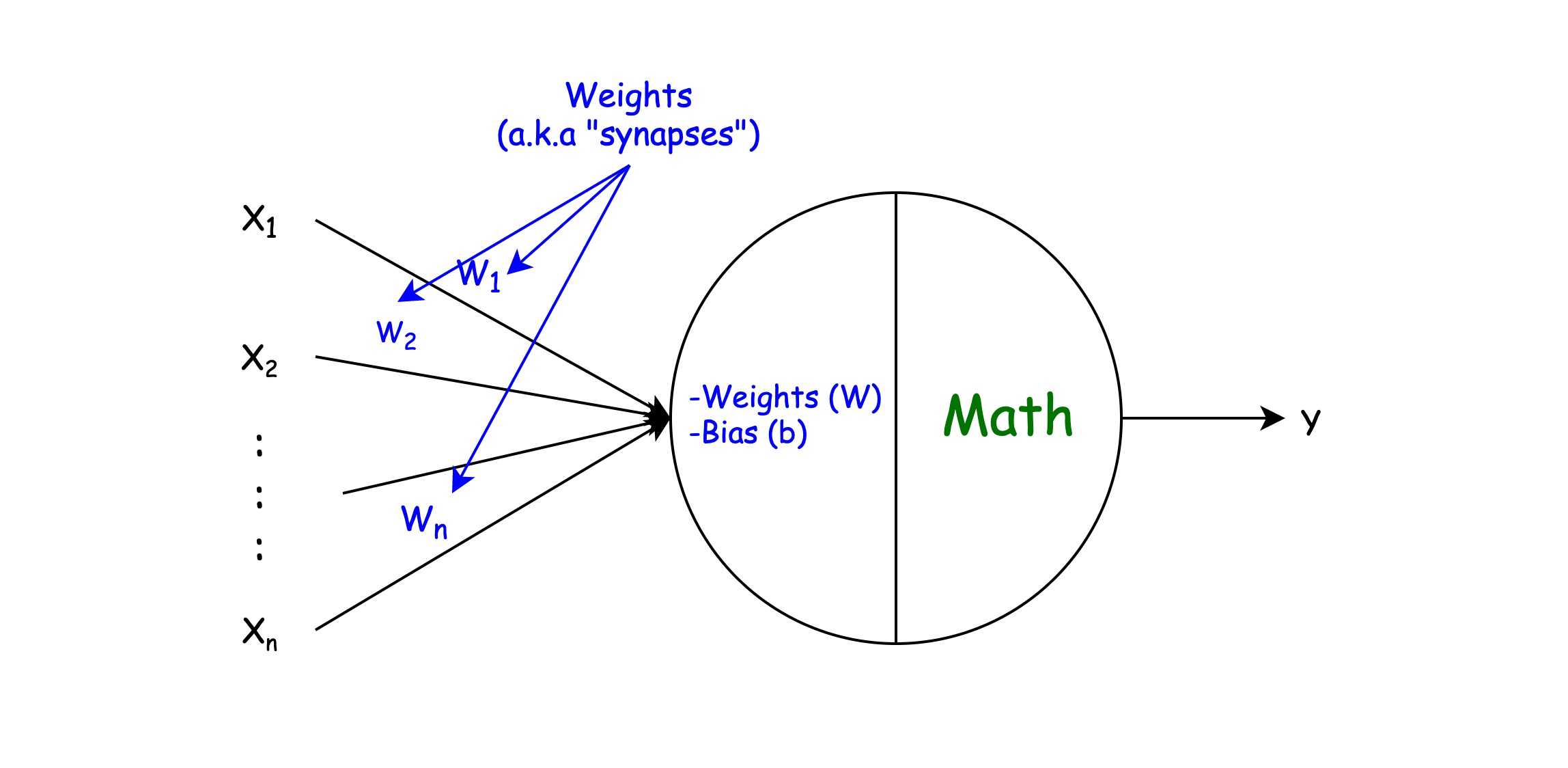
It is worth to mention that Neuron is just a concept, and underlying implementation of Neural Network may not contain exact neuron as an object/class.
So if to compare to biological neuron, then:
- X — and input data (a.k.a signals received in dendrites)
- Weights & bias — the strength of a connection between neurons (a.k.a synapses)
- Math — an algorithm to modify X, Weights, and bias in order to get some output Y (a.k.a cell body)
- Y — an output value (a.k.a signal passed to axon)
Detaching from comparison with a biological neuron, an artificial neuron is simply a unit, that:
- has an array of numbers called weights corresponding for each input (x)
- has a constant number bias
- has an underlying math algorithm, that decides how to turn input data to output
What is a Neural Network?
Surprisingly, the above representation of a neuron is itself the smallest possible Neural Network called a Perceptron. Perceptron can even classify simple linear patterns.
However, for more complex problems, like for instance detecting if an image contains a cat, much more are neurons needed.
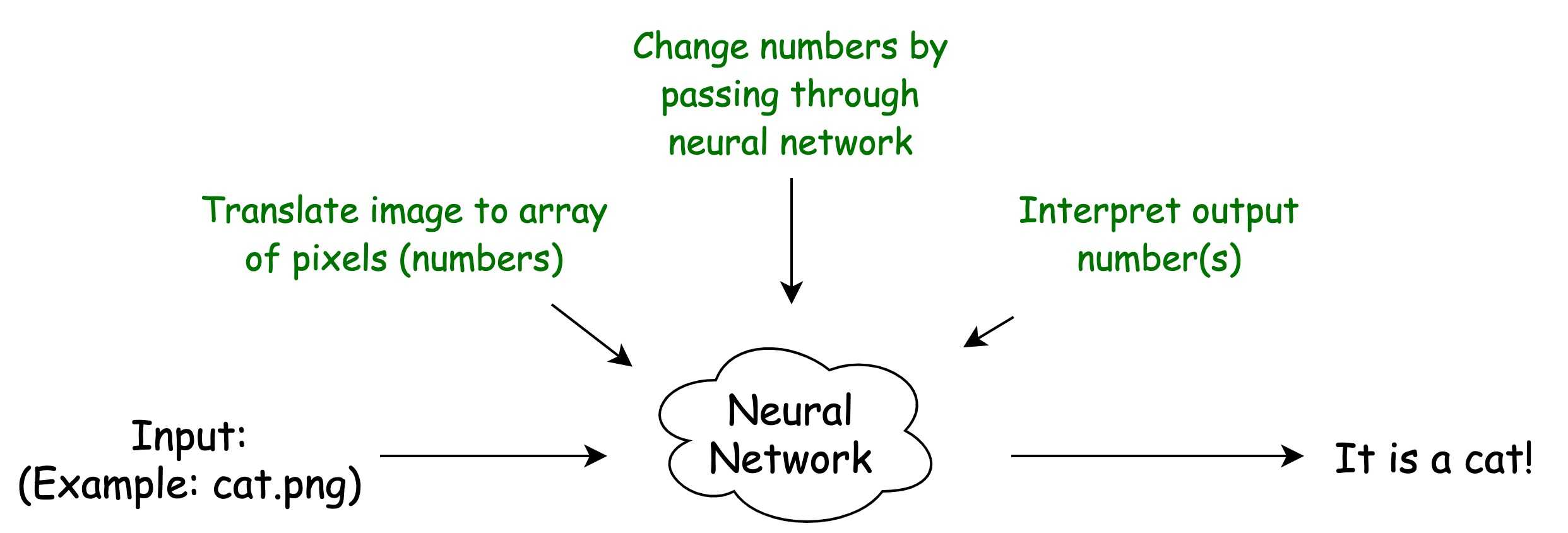
However, preparing input data and interpreting output data is still a bunch of algorithms that are on you.
For example, image recognition is done first by converting an image into an array (vector) of pixels. Then you run your pixels through Neural Network and get some output data which you then interpret back as some meaningful answer:
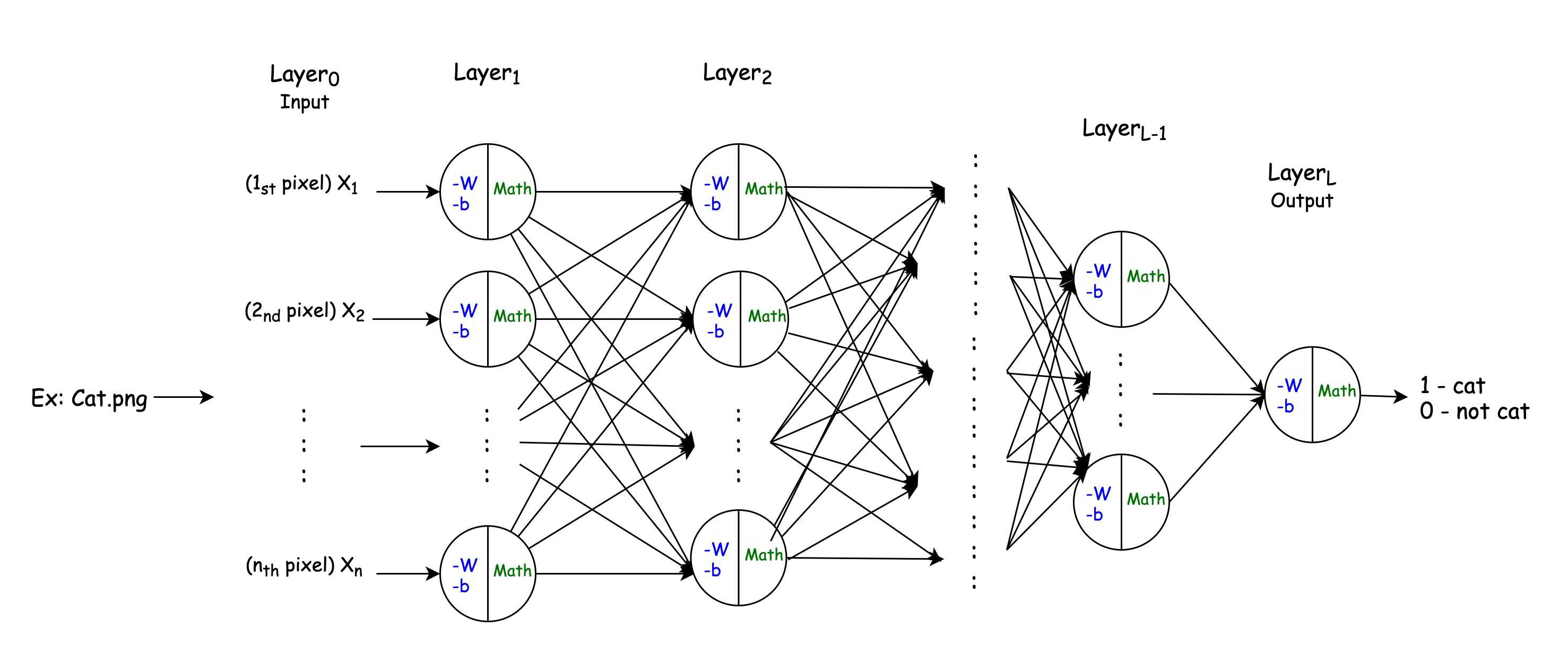
The first question is how does our neural network know how to change the input in order to get the correct output? The answer is that initially, it does NOT.
In order to get the correct answers, we need to train a Neural Network.
Training a Neural Network
In short, the whole training process of a Neural Network is about finding the right values of weights and bias for each neuron in each layer, so that we start getting correct results.
In order to train, first, we need to have some examples. In our case, we need lots of cat & non-cat images.
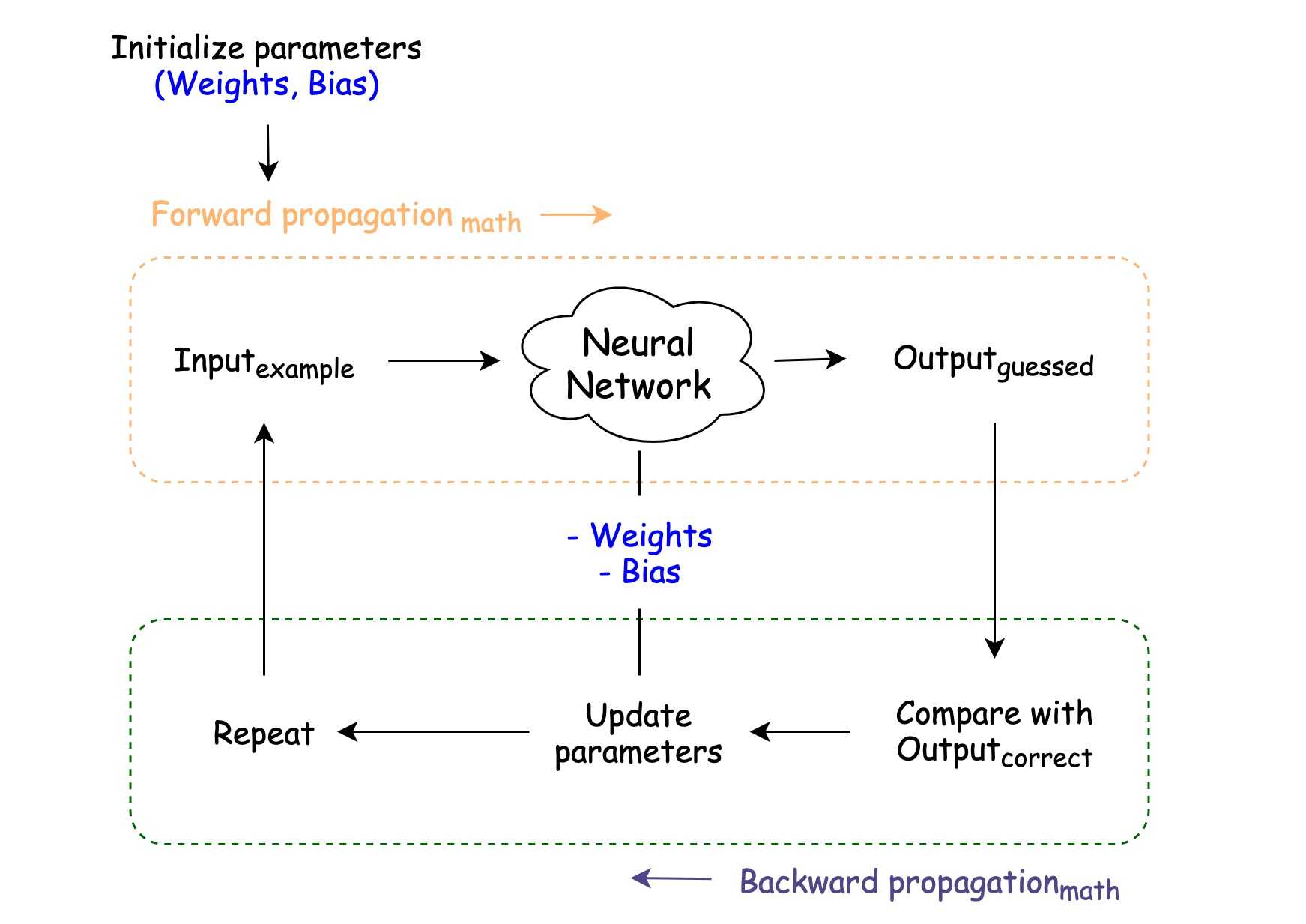
- Parameters initialization — initializing weights and bias. Usually, it is a random initialization, with a bit of math.
- Forward propagation — a process of guessing an answer using some math
- Backward propagation — a process of adjusting parameters according to guessed answer and correct answer using some math
Unless you’re going to invent new techniques for parameter initialization, forward & backward propagation, all math is a bunch of formulas & algorithms, which can be found in google.
Moreover, almost all deep learning frameworks, such as TensorFlow, already has lots of predefined implementations and you don’t have to write yourself math part. However, in order to better understand Neural Networks it is suggested to try implementing yourself.
Besides the above steps, the performance (correctness of answers) of Neural Network also depends on things like:
- Initialization algorithm
- Number of layers
- Activation function (algorithm) for each layer
- Number of units (neurons) in each layer
- Number of training examples
- Number of iterations you make during training (number of “forward” & “backward” propagations)
- Learning rate, a constant number which used during the parameters update step in each iteration
- And other Neural Network architecture-specific decisions
Using a Neural Network
All information you end up having after Neural Network training, such as how many layers, how many units (neurons) in each layer, which activation function is used in each layer, adjusted weights & bias is together called a model.
So, using Neural Network with real data is just taking that model and running through forward propagation (guessing) in order to get and output (answer).
Going Further
Above is just a general overview of Neural Networks and how they work.
However, there are different types of Neural Networks, differing by architecture and underlying algorithms. Each type has its own PROs/CONs and used to solve different types of problems. Following are just a few popular examples:
- Convolutional Neural Networks (CNN)— usually used for classification problems, such as image processing, computer vision, speech recognition, etc
- Recurrent Neural Networks (RNN) — used when the context is important, like translations, text to speech, autosuggestion such as grammar checks, etc
- And many others…
Summary
So, Neural Network is all about changing the input to get some output. However, we don’t write rules for how to change that input, but instead, we show Neural Network lots of examples and rely on math to get rules. Then we use the latter with real examples.
Hopefully, you got the general idea of Neural Networks. However, in order to become a Deep Learning expert and solve real-world problems, you need a bit of patience, at least basic calculus knowledge, and most importantly to keep learning as well as practicing solving problems.
More articles are coming related to this topic:
- Building a Perceptron from Scratch
- Building a Deep Neural Network from Scratch